The DFIR.. what?
For the last couple of years I have tinkered around a docker-compose configuration for launching DFIR investigation system. The original one was created with four components:
- ELK - ingesting all the data with all the visualisations
- PLASO - parse all the Windows evidence
- Chainsaw - parse evtx logs
- Hayabusa - parse evtx logs
This was a good start and I used it especially with different CTF’s and such. However it did get a bit heavy so I started to revamp it, reusing the old components partly. The new version will have only partial functions implemented for now, mainly the Chainsaw and Hayabusa parts of the old set but they have been polished a bit.

Current version
The current version is a combination of three different docker-compose files which are launching a set of different containers. The following diagram represents the three files:
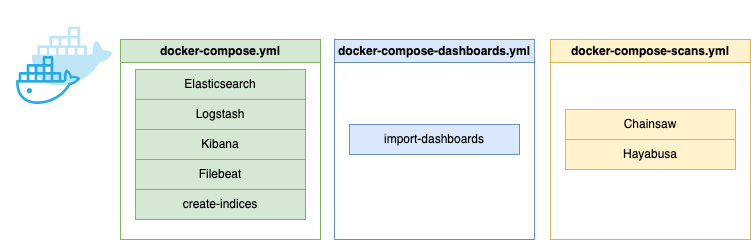 The docker compose containers.
The docker compose containers.
Docker-compose.yml
This is the main configuration which launches the ELK stack, Filebeat and also a container known as create-incides. The create-indices container is creating the indices for Chainsaw and Hayabusa. The reason for running the container is that if it is not done the Hayabusa ingestion will fail. Some of the fields on Hayabusa output has wrong data type so if the ELK is automatically setting the contents it is likely that those fields will be set to numerical values and some of the other content can’t be ingested because of wrong data type. The creation of the indices makers sure that those fields are set as string data type. Also it adds limitation of unique fields to 2000, which is also required as I am using the super-verbose option on Hayabusa which creates a massive amounts of fields.
Beware! Although this fixes most of the ingestion issues of Hayabusa it is still not able to ingest 100% of events; the details field should be an object but on some events it contains concrete data. Those fields will be sent to Dead Letter Queue as they can’t be parsed.
Docker-compose-dashboards.yml
This file is fairly simple. It is importing the Kibana saved objects to the ELK stack so that the visualizations are available. It needs to be run separately at your own will.
Docker-compose-scans.yml
This one is launching the Chainsaw and Hayabusa containers. The containers target the case_data subfolder - all the EVTX files which you would like to parse should be placed to this folder before running the container.
Using the DFIR thing
It should be relatively easy to use for anyone who has support for docker. Follow these easy steps:
- Clone the Git repository
- Place your EVTX files to the case_data folder. Chainsaw and Hayabusa are able to find them from subfolders so the structure is not very important.
- Start the ELK stack (in root of the cloned repo): docker-compose up -d
- Wait for the stack to start. Browse to http://localhost:5601 to see that the ELK stack is up and responding. There should be two indices now.
- Import dashboards with the following command (in root of the cloned repo): docker-compose -f docker-compose-dashboards.yml up
- You should now be able to see the dashboards.
- I suggest to remove the container: docker-compose -f docker-compose-dashboards.yml down
- To parse your evtx logs from the case_data folder run the following command: docker-compose -f docker-compose-scans.yml up
- After Chainsaw and Hayabusa containers are successfully launched the data is automatically picked up by Logstash and sent to elasticsearch. The Kibana dashboards should be working.
- Remove the scans container: docker-compose -f docker-compose-scans.yml down
- Start forensicating using Kibana.
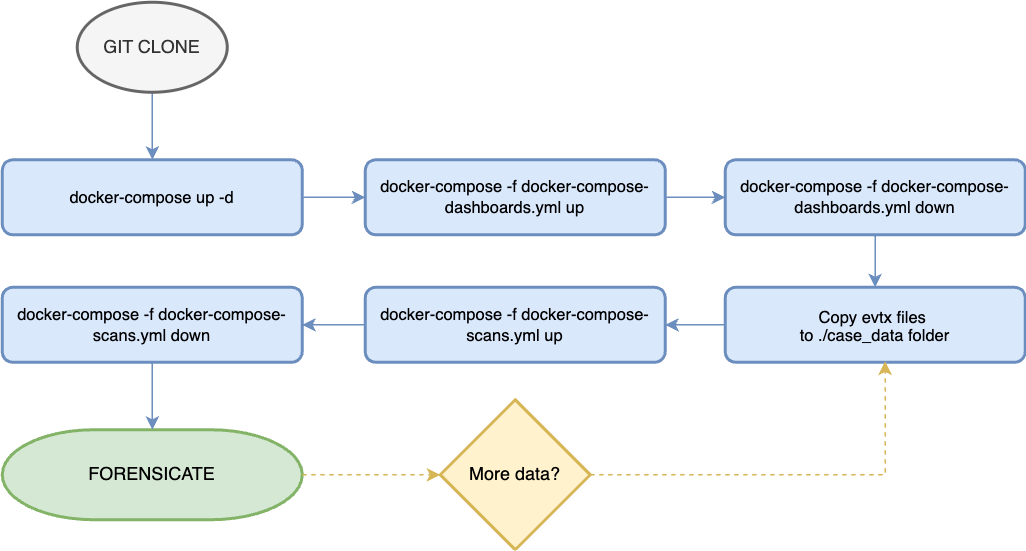 Steps to run the DFIR thing.
Steps to run the DFIR thing.
Dashboards
The dashboards are VERY straight forward.
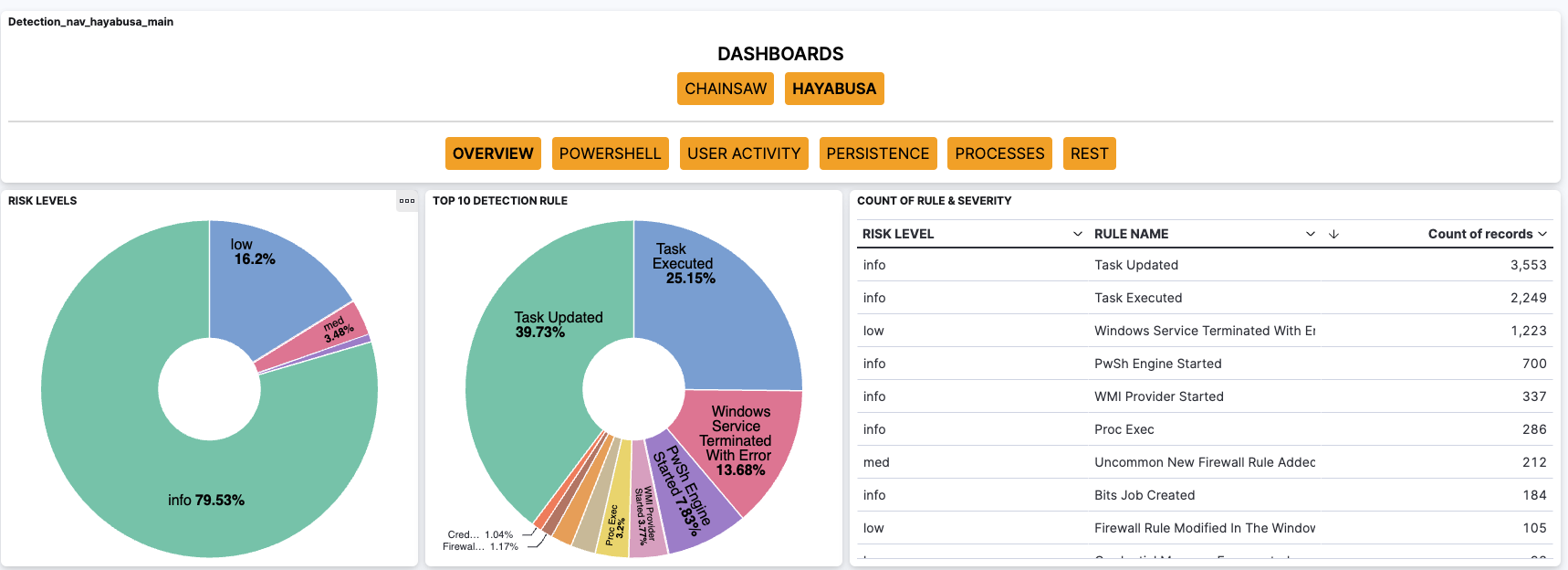 The dashboards on Kibana.
The dashboards on Kibana.
The overview gives you an overview of the data. At the bottom of the page (actually bottom of all the dashboards) you can find a timeline of the data where you can see all the events which hit the filters.
- Overview: All the events, no filters. The timeline at the bottom of the dashboards only has high level information
- Powershell: Powershell related events.
- User activity: Mostly logon events, but also has things like group additions
- Persistence: Persistence related events.
- Processes: Process launches.
- REST: All the events which do not hit on the previous filters.
The Chainsaw is quite similar but it is more limited. Honestly, the Hayabusa brings in much more details and data so I think it is a better tool for this particular approach. I might remove Chainsaw completely in the future, the reason why I have both is that I wanted to learn how this approach works, create the containers, and all that. So it was mostly for my personal learning experience.
File structure
The file structure is explained below.
- case_data/ - contains all the evtx files to be parsed. Empty when a clean env is cloned.
- chainsaw/ - contains the chainsaw docker image.
- config/ - contains the config files for ELK stack.
- dashboards/ - contains the dashboards to be imported to Kibana.
- elasticsearch/ - contains the elasticsearch persistent data.
- filebeat/ - contains ingestion for couple of web servers by filebeat. Not really used currently but you can use it to ingest web server logs. No dashboards or anything.
- hayabusa/ - contains the Hayabusa docker image.
- logstash/ - contains the logstash files, the configurations, ingestion folders for the data, persistent data.
- docker-compose-dashboards.yml - importing the dashboards.
- docker-compose-scans.yml - running Chainsaw and Hayabusa.
- docker-compose.yml - running ELK.
- createindices.sh - used by the ELK configuration for creating the indices over the API.
- import.sh - used to import the dashboards over the API.
Final words
This is fairly straightforward way of ingesting EVTX files and quite a large amount of them. Investigating should be quite easy with the help of the dashboards and it may provide to be useful especially when starting an investigation. It is far from complete especially as it currently support only EVTX files. Something like SOF-ELK is much more complete solution for investigating, however I myself MUCH prefer containers which is why I started to build this out.
What it is for you? I guess it can be used out of the box to get started but it could also be used to build upon on your own needs. The basic idea is functioning really well imo but it is just missing the configurations for other file types than EVTX. I do not intend to make this a huge project which I would constantly work on but wanted to release this so that you may have a look and determine if you enjoy it.
It is one of my hobby projects which I hope to update in the future though. I do plan on extending this. Next steps will likely include support for Loki scan and or Registry parsing (likely with Regipy).
Links: